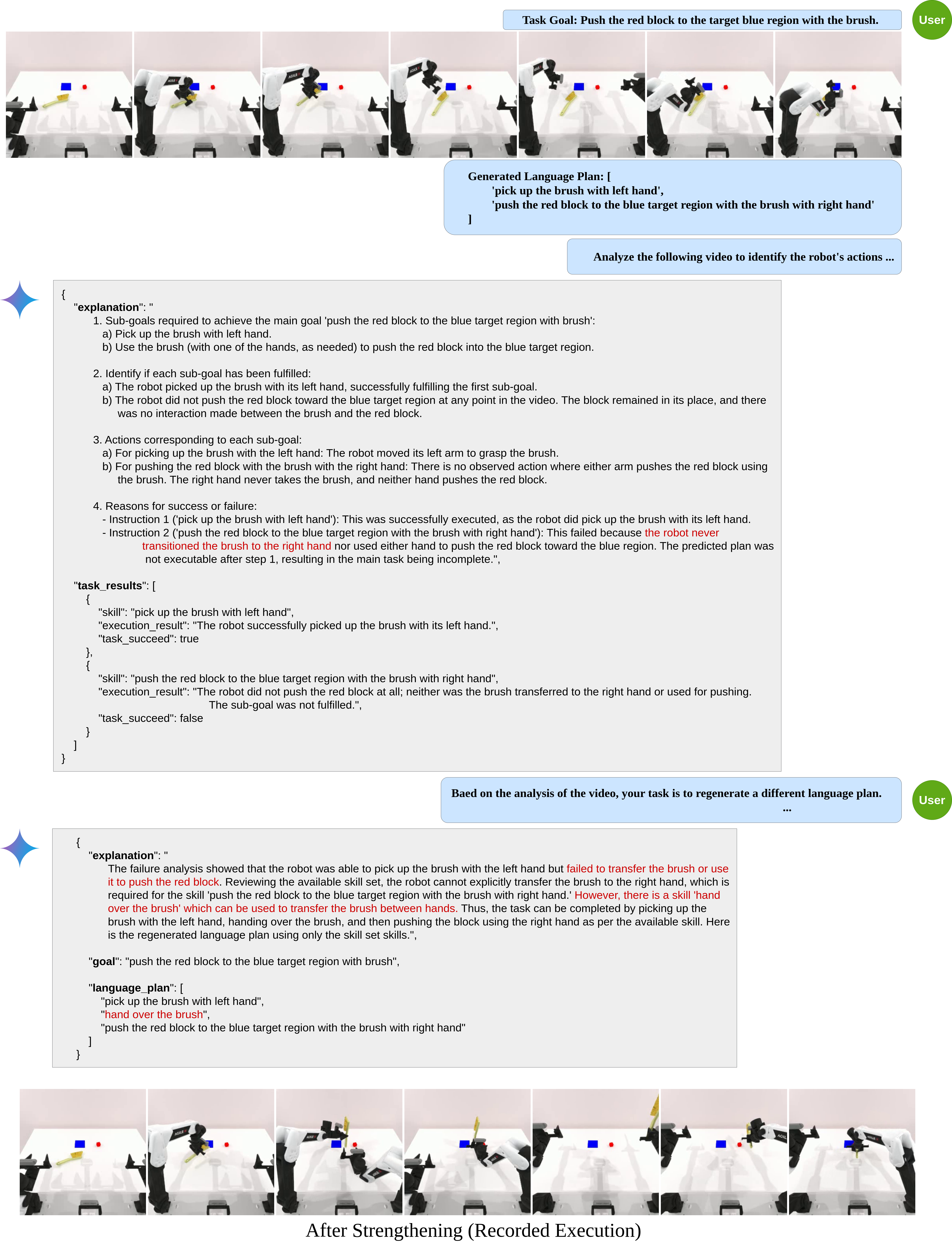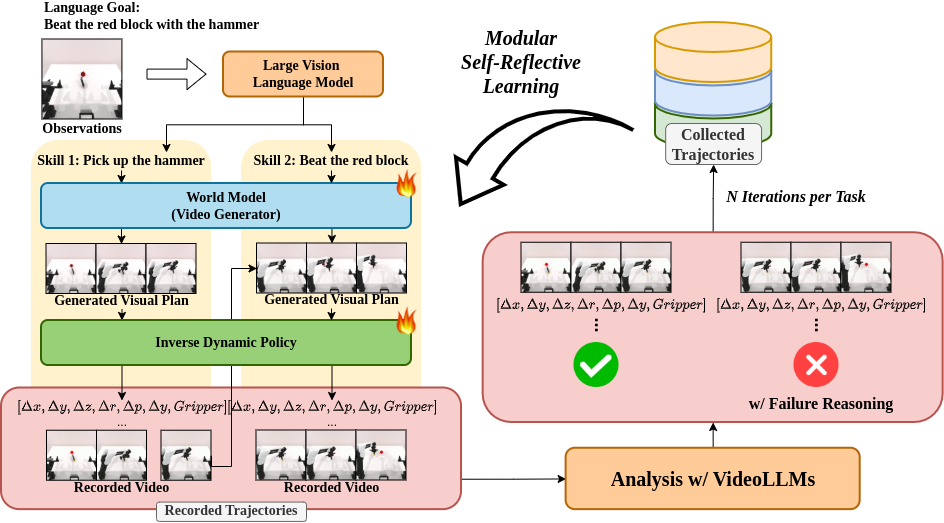
In each trajectory, we identify the cause of failure modes and leverage this information to iteratively improve compositional foundation models for robotic decision-making.
Enabling robots to autonomously perform complex, long-horizon tasks remains challenging due to the need for hierarchical reasoning and dynamic adaptability. Humans overcome this by interacting with environment and learning from their own experience, which is infeasible for existing robots without human supervision. To enable similar capabilities in robotic agents, we introduce MOSEL, an modular self-reflective learning framework for robotic decision making. MOSEL combines hierarchical planning with multimodal foundation models, including LVLMs, video diffusion, and inverse dynamics models. These components work together to break down complex tasks, generate executable visual plans, and perform actions. We further introduce a modular self-reflective learning framework that autonomously identifies failures and iteratively refines policies with minimal human intervention. Evaluations on LIBERO-LONG and RoboTwin benchmarks demonstrate that MOSEL outperforms existing methods, achieving over 33% and 46% average performance improvements, respectively. Our results underscore the effectiveness of autonomous self-improvement and accurate failure identification in advancing robust robotic manipulation.

LIBERO
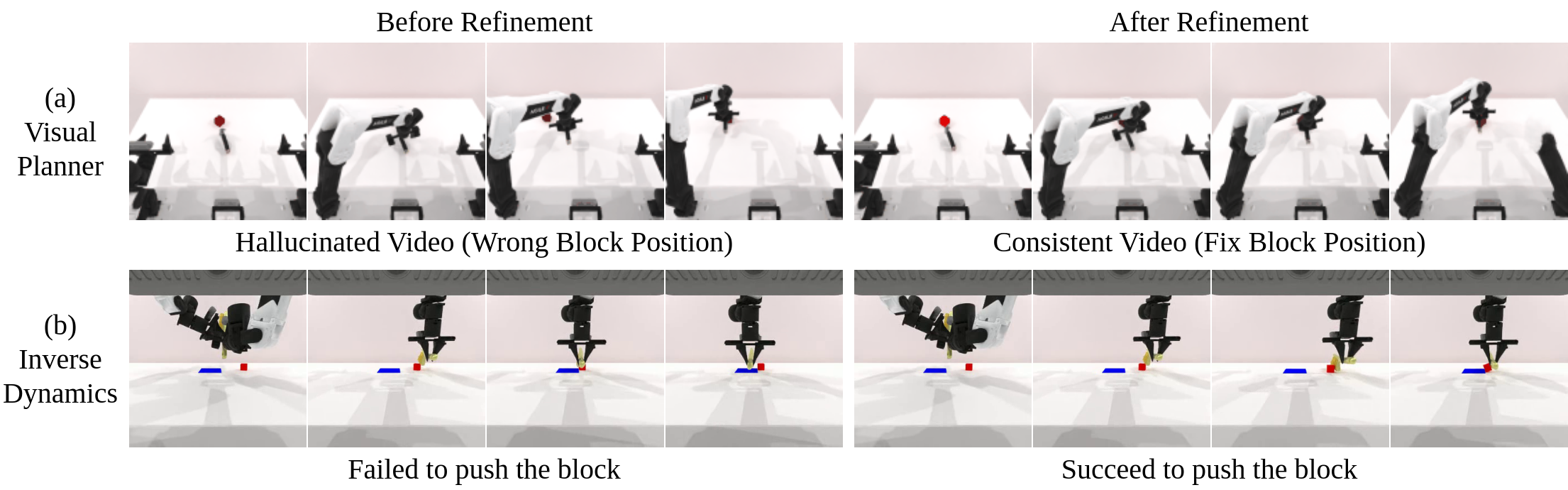
RoboTwin